Golang : Creating a concurrent worker pool
Introduction⌗
There are several concurrency models supported by different programming languages. For example, actor-based concurrency model in Erlang and Akka toolkit, Thread based concurrency in Java and Futures and Promise based concurrency in functional programming languages like Closure.
Go advocates concurrency using a programming model called CSP (communicating sequential processes), which breaks a problem into smaller sequential processes and then schedules several instances of these processes (Goroutines). The communication between these processes happens by passing immutable messages (via Channels). These basic language constructs help Go developers to create innovative design patterns like pipelines, fanIn, fanOut, Timeouts, rate-limiting, etc.
In this blog post, we will create a basic worker pool using Goroutines and Channels and examine the improvements in throughput. All the code discussed in this blog post is available here. If you have any questions or queries, please create an issue here and I will be more than happy to clarify them.
TLDR;⌗
By applying the worker pool pattern (16 concurrent workers) in this example, we managed to reduce the processing time for the same batch size from 17.25387443 Seconds to 1.494497171 Seconds.
Worker Pool pattern⌗
Worker pool pattern is a useful design pattern to processes individual work items in large batch sizes. It is a way to divide the M number of tasks in a pool amongst N workers to achieve maximum efficiency. In this design pattern, a master (or dispatcher) is responsible for collecting individual work items (or jobs) and distribute them amongst workers for concurrent processing. In our example, the dispatcher will also be responsible to spawn N number of workers.
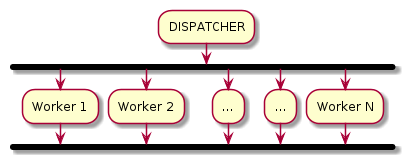
To keep this example simple, I have not implemented the complete lifecycle management of the workers (i.e. creating and shutting down workers and the dispatcher gracefully).
Problem statement⌗
To simulate a batch process, we have a list of ids for civilizations in the game of Age Of Empires-2. For each id in the list, we send an http.GET request to this endpoint and get a response in the below format.
|
|
To create a baseline for comparison, we call this endpoint sequentially in a loop like below.
|
|
The detailed implementation is available here. Readers are encouraged to clone the repository and run it themselves to see the response times. I have taken an average of 10 executions which turns out to be around 17.25387443 Seconds. In the next section, we will create a worker pool and compare the improvements in response time.
Implementing the Worker(s)⌗
We start by defining a basic unit of Work called a Job. A Job represents a single entity that should be processed. We also define another struct called Worker, which acts as a task processor. All the workers share a common JobChannel where each Job is received for processing, a Queue which is shared between all the workers and the dispatcher. The Queue stores the JobChan of all the workers.
|
|
Each of the worker has a Start() method, which spawns a goroutine in the background. Whenever a worker is available (unblocked state), it places its JobChan in the Queue and blocks to receive a Job. Whenever a job is received, it is sent for processing callApi(). More details on the worker implementation is available here.
Please note that any business logic or process should be implemented closer to the worker. If there are any dependencies (like database connections, http clients, etc) the constructor for a worker is a good place to inject them.
Implementing the dispatcher⌗
The implementation of the Dispatcher is very straightforward. The dispatcher consists of a slice of workers, a JobChannel, where it can receive individual jobs from clients and a JobQueue which is shared with the individual workers. The number of workers is controlled through the dispatcher’s constructor New(num int).
|
|
The dispatcher is triggered by calling its Start() method. We also have a Submit() method which is available to the client to add new Jobs.
|
|
The Start method initializes new workers, shares the dispatcher’s JobQueue with workers and starts listening to the submitted job by running its process() method in the background. The process method listens for any submitted job on dispatcher’s WorkChan, then waits for a worker to place its JobChan on the JobQueue. Once an available JobChannel is found, the job is placed on it so that the worker can process it. Readers can find the complete implementation here.
Starting the worker pool and submitting the Jobs⌗
We use the same list of tasks, but instead of calling the API in sequence, we distribute it concurrently among 16 workers via the dispatcher. I have taken an average of 10 concurrent executions which turns out to be 1.494497171 Seconds. I encourage the interested readers to clone the repository and try out these examples.
|
|
Conclusion⌗
Go provides some excellent constructs for managing concurrency. Moreover, the CSP based concurrency model is easier to mentally visualize as the core business process can still be written like we always do. Their executions can be scheduled concurrently using Goroutines and Channels. Goroutines and Channels strike a nice balance between power and flexibility and simplifies asynchronous programming by allowing developers to write synchronous code.
Thanks for reading !!